概述#
丢弃法在每一次 SGD 中对(全连接的)隐藏层中的每个元素进行如下扰动:
\begin{flalign} & \boldsymbol{w}_i' = \left\{ \begin{array}{llll} \boldsymbol{0} \quad&\text{with probability } p,\\ \displaystyle{\boldsymbol{w}_i\over 1-p} \quad&\text{otherwise}. \end{array} \right. & \end{flalign}可以发现,经过扰动之后的 的期望没有改变,即
由于是在每一次 SGD 中进行的,故而可以视作一个层,链接在隐藏层的输出或者其 ReLU 层后。
详述#
实质#
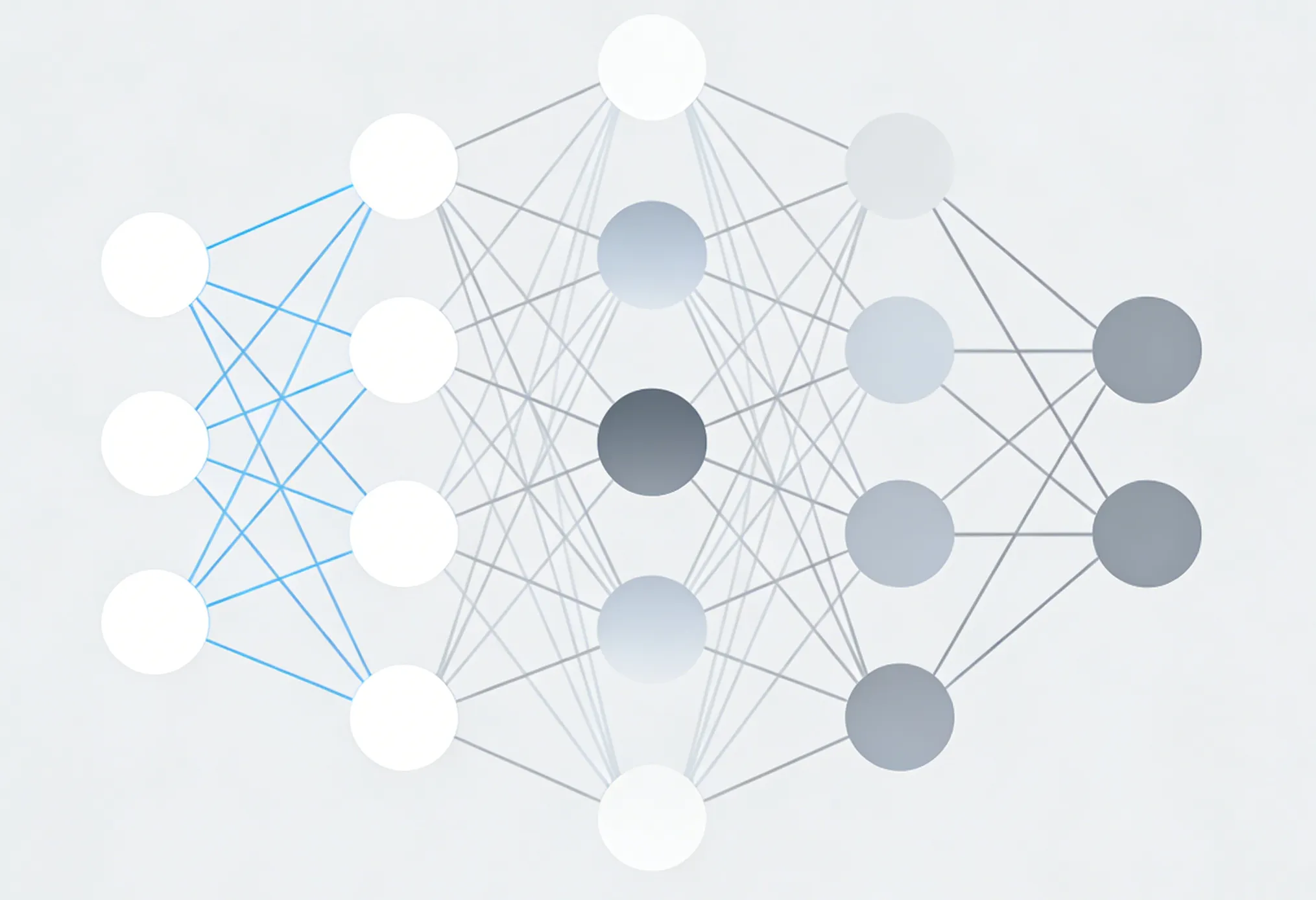
本质是在训练的时候,随机挖除一些隐藏层神经元:
![[./images/Pasted image 20251118142821.png]]
丢弃的时机是在隐藏层计算完成、还没输出到下一层的时候,而不是直接在 上操作。
在推理的时候,不再 dropout,使用全规模的网络。
原理#
关于其为什么能够增加模型的鲁棒性、抑制过拟合,有两种说法:
- Hinton(dropout 的提出者)认为,丢弃法相当于训练了多个的子神经网络,最终将它们整合为一个 ensemble,每次推理的时候多个子神经网络的推理结果取平均,做了一个 voting,因此结果更可靠
- 后来的实验、测试表明,丢弃法更像是一种正则,其在隐藏层制造噪音,使得模型整体更加 robust;
另一种感性的认识:dropout 类似于生命体的代偿机制,一个器官病变,其他器官会来 参与补偿它的功能。![[./images/IMG_3942.png]]
实践#
有了 dropout,我们可以将模型隐藏层设得大一点,给模型更多潜力,同时使用 dropout 限制过拟合。这样的效果往往比不使用 dropout 而单纯减小隐藏层大小来得要好。
import torch
from torch import nn
from d2l import torch as d2l
def dropout_layer(X, dropout):
assert 0 <= dropout <= 1
if dropout == 1:
return torch.zeros_like(X)
if dropout == 0:
return X
mask = (torch.rand(X.shape) > dropout).float() # 这么秀的写法?!
return mask * X / (1.0 - dropout)
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
class Net(nn.Module):
def __init__(self, num_inputs, num_outputs, num_hiddens1, num_hiddens2,
is_training = True):
super(Net, self).__init__()
self.num_inputs = num_inputs
self.training = is_training
self.lin1 = nn.Linear(num_inputs, num_hiddens1)
self.lin2 = nn.Linear(num_hiddens1, num_hiddens2)
self.lin3 = nn.Linear(num_hiddens2, num_outputs)
self.relu = nn.ReLU()
def forward(self, X):
H1 = self.relu(self.lin1(X.reshape(-1, self.num_inputs)))
if self.training == True:
H1 = dropout_layer(H1, dropout1)
H2 = self.relu(self.lin2(H1))
if self.training == True:
H2 = dropout_layer(H2, dropout2)
out = self.lin3(H2)
return out
net = Net(num_inputs, num_outputs, num_hiddens1, num_hiddens2)
num_epochs, lr, batch_size = 10, 0.5, 256
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
trainer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)import torch
import torch.nn as nn
num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784, 10, 256, 256
dropout1, dropout2 = 0.2, 0.5
num_epochs, lr, batch_size = 10, 0.5, 256
net = nn.Sequential(nn.Flatten(),
nn.Linear(num_inputs, num_hiddens1),
nn.ReLU(),
nn.Dropout(dropout1),
nn.Linear(num_hiddens1, num_hiddens2),
nn.ReLU(),
nn.Dropout(dropout2),
nn.Linear(num_hiddens2, num_outputs))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.SGD(net.parameters(), lr=lr)
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, trainer)总结#
- 丢弃法将一些输出项随机置 来控制模型复杂度
- 常作用在多层感知机的隐藏层输出上
- 丟弃概率 是控制模型复杂度的超参数
丹方#
调参可以优先试 这三个值